
여는 말
안녕하세요. SK텔레콤 최준승입니다. 오늘은 연재 8번째 시간이고요. 주제는 네트워크 영역의 사용량을 최적화하는 법입니다. 연재물의 본론은 크게 6개의 영역으로 나눠서 클라우드 비용을 최적화하는 법을 다루고 있는데요. 오늘이 본론으로는 마지막 회차입니다. 지금까지 연재를 함께해 주신 독자분들은 이미 느끼셨겠지만 비용 최적화 전략들은 서로 엄격하게 분리되어 있지 않고요. 때로는 시너지의 관계로 때로는 Trade-off의 관계로 서로 밀접하게 연결되어 있습니다. 그러므로 여러분들은 이런 복합적인 재료의 특성을 먼저 이해하고, 여러분들의 환경에 적합한 방식으로 "각자의 최적화 요리"를 만들어낼 필요가 있습니다.

다시 오늘의 주제로 돌아와서 네트워크 사용량의 특수성을 논해봅시다. 네트워크 – 단가 편에서도 언급했던 것처럼 클라우드 환경의 네트워크 사용량은 상수가 아닌 변수에 가깝습니다. 예를 들어 AWS 환경에서 빌링 데이터를 UsageType으로 구분해서 보면 고정 수량의 노드 비용 항목은 매일 일정한 패턴으로 사용량(노드 수 x 24시간)이 잡히고요. 네트워크 관련 (*-Bytes 같은 이름으로 구분된) 항목들은 들쭉날쭉한 사용량 패턴을 보이는데요. 이는 각 구간별로 오가는 트래픽의 양이 (클라이언트 수나 요청 패턴 같은) 외부 요인에 따라 가변적으로 움직이기 때문입니다. 따라서 사용량을 사전에 정교하게 예측하기도 어렵고 단가가 곱해져서 산출되는 네트워크 비용도 가늠하기 어렵습니다.

그럼에도 불구하고 서비스의 규모가 커지고 구성된 컴포넌트 수를 손가락으로 셀 수 없는 시점이 오면, 네트워크 비용은 전체 비용에서 무시할 수 없는 수준으로 증가합니다. 하지만 여전히 클라우드 환경의 네트워크 비용 분석은 어렵습니다. 비용 개선활동 또한 ROI가 나와야 하는데 투입 관점에서 분석 난이도가 생각보다 높기 때문입니다. 하지만 어려워도 필요하면 해야죠. 일정 수준 이상의 Finops 환경에 도달하게 되면 네트워크 비용 최적화는 반드시 필요해지고 이는 여러분도 예외가 아닙니다. 오늘은 "네트워크의 사용량을 최적화한다"라는 의미를 먼저 정의한 후에, 이어서 네트워크 사용량의 규모를 조정하는 세부 전략 몇 가지를 살펴보도록 하겠습니다.
하나, 네트워크 사용량을 최적화한다는 것은?
첫 번째 주제로 "네트워크 사용량 최적화"의 뜻을 함께 정의해 보겠습니다. 결론부터 말씀드리면 네트워크 영역은 (방법론 측면에서) "단가 최적화"와 "사용량 최적화"를 기계적으로 분리하기 어렵습니다. 반면 컴퓨팅이나 스토리지 영역은 단가 최적화 전략과 사용량 최적화 전략을 구분해서 보기 어렵지 않은데요. 적용 관점에서도 두 가지 트랙을 선택적으로 나눠서 진행할 수 있습니다. 예를 들어 1) 컴퓨팅의 단가 관점에서 Right-Sizing을 하거나 약정을 적용하고 2) 컴퓨팅의 사용량 관점에서 스케줄링을 반영하는 것처럼 과제들을 분리해서 진행하는 것이 가능합니다. 물론 네트워크도 이런 식의 구분이 가능하지만 적용 관점에서 때로는 그 구분이 모호해지거나 불필요해지는 경우가 많습니다.
다시 원점으로 돌아와서 Finops 팀의 에이스인 여러분에게 새로운 미션이 주어졌다고 가정해 봅시다. 미션명은 네트워크 비용 최적화입니다. 단가로 접근할지 사용량으로 접근할지는 지금 중요치 않습니다. 이때 여러분들이 제일 먼저 해야 할 일이 무엇일까요? "클라우드 비용 최적화 로드맵"의 5회차와 8회차를 다시 정독하는 것? 물론 이것도 정답입니다만 더 중요한 것은 여러분 환경의 사용 패턴을 "제대로" 분석하는 것입니다. 여러분들이 운영하고 있는 클라우드 환경 기준으로 1) 구간별 네트워크 사용량을 계측하고 2) 구간별 단가 정책과 결합하여 3) 현재 가장 많은 비용이 발생하고 있는 영역부터 식별해야 합니다.

위 그림은 AWS 환경 내외의 구간별 과금 여부를 추상화해서 그린 것인데요. 하나씩 살펴보면 ①은 동일 AZ 내 트래픽입니다. 일부 예외는 있지만 대체로 무료 구간이라 초록색으로 표시했고요. ②는 타 AZ 간 트래픽입니다. AWS의 빌링 데이터에서는 UsageType이 [리전명]-DataTransfer-Regional-Bytes로 찍히고요. 유료 구간이라 주황색으로 표시했습니다. ③은 타 Region 간 트래픽입니다. UsageType은 보통 [리전명1]-[리전명2]-OUT-Bytes 항목으로 구분됩니다. 역시 유료 구간이고 대상 리전에 따라 단가가 다릅니다. ④는 AWS와 인터넷 간에 오고 가는 트래픽입니다. AWS에서 인터넷 구간으로 나가는 것은 유료, 인터넷 구간에서 AWS로 들어오는 것은 대개 무료입니다. 전자의 유료 구간은 UsageType이 [리전명]-DataTransfer-Out-Bytes인 항목을 봅니다. 기타 나머지 항목들은 따로 구글링해 보시면 AWS에 좋은 참고 글이 많기 때문에 여기서는 추가 설명을 생략하겠습니다.
여기서 핵심은 "여러분들의 환경 기준으로" 위에서 말씀드린 구간별 사용 패턴을 분석할 수 있어야 한다는 것입니다. 과거 비용 데이터를 기반으로 어느 구간에서 사용량이 많이 잡히고 있는지, 그게 유료 구간이라면 얼마의 비용이 발생하고 있는지를 상세하게 들여다봐야 합니다. 여기서 "상세하게"의 의미는 단순히 구간별 전체 비용이 아닌 특정 자원(EC2 인스턴스, S3 버킷 등)별 사용량을 구분해서 보는 것을 포함하는데요. 예를 들어 서울 리전의 DataTransfer-Out 비용이 월 100만 원이 나오고 있다면, 그 Source가 어떤 인스턴스인지 / 어떤 ELB인지 / 어떤 S3 버킷인지까지 구분해서 분석할 줄 알아야 합니다. 필요에 따라 시점을 일(Daily) 단위로 분리해서 사용 패턴을 분석할 수도 있습니다. 위에서 말씀드린 항목 외에도 Transit Gateway나 NAT Gateway 같은 관리형 객체의 사용량도 함께 살펴봐야 합니다. 분석 과정에서 비용 데이터 외에 VPC Flow Logs 같은 별개의 데이터를 참조해야 할 수도 있습니다.
우여곡절 끝에 분석이 완료되었습니다. 여러분은 어느 구간의 네트워크 비용이 (+어떤 자원으로부터) 많이 발생하고 있는지를 데이터로 확인했습니다. 그럼 그다음에는 무엇을 해야 할까요? 비용이 상대적으로 큰 구간의 사용량을 어떻게 줄일 수 있을지를 고민해야 합니다. 해당 구간의 사용량이 유의미한지 / 유의미하다면 해당 구간의 사용량을 임의로 줄일 수는 없는지 / 줄이는 것이 불가능하다면 더 낮은 단가의(또는 무료의) 구간으로 경로를 재배치할 수 없는지를 순차적으로 검토해야 합니다.

위 그림의 Case1처럼 전송량 자체를 줄이는 기법은 여러 가지가 있습니다. 일반적인 Client-Server 구조에서 요청 및 응답 패턴을 최적화하거나, 캐싱이나 압축 같은 부가 기술을 활용할 수도 있습니다. 만약 데이터 전송량을 물에 비유한다면, Case2처럼 전체적인 水량은 그대로 유지하되 물길을 바꿔서 더 낮은 단가(또는 무료)의 경로로 물이 흐르도록 만들 수도 있습니다. 예를 들어 복수의 인스턴스로 구성된 클러스터 간에 데이터를 주고 받을 때 일부 Cross-AZ 간 트래픽을 동일 AZ 간 트래픽으로 유도한다면, 전체적인 전송량은 비슷할 수 있지만 일부 트래픽이 무료 구간으로 대체되면서 총비용은 크게 달라질 수 있습니다.
제가 이번 장에서 말씀드리고 싶은 것은 최적화 관점에서 위 Case1과 Case2를 명확하게 구분하는 것이 큰 의미가 없다는 것입니다. 보는 관점에 따라 Case1을 Case2로 볼 수도 있고 Case2를 Case1로 볼 수도 있습니다. 두 가지 Case의 공통 목표는 "상대적으로 단가가 높은 유료 구간"의 네트워크 사용량을 어떻게든 최소화시키는 것입니다. 오늘 뒤에서 소개하는 사례들 또한 이 두 가지 Case를 엄밀히 구분하지 않고 혼용하여 다루도록 하겠습니다.
둘, 캐싱을 써보는 건 어떨까?
네트워크의 사용량을 최적화하는 첫 번째 전략은 캐싱(Caching)입니다. 캐싱의 사전적인 개념은 자주 사용되는 데이터를 임시 저장하여 빠르게 접근하는 기술인데요. 개념 일부를 확장하면 가까운 곳에서 동일한 응답을 재활용하는 것입니다. 캐싱은 다양한 계층에서 다양한 방식으로 구현할 수 있습니다. 일반적인 Client-Server 구조의 웹서비스를 한번 생각해 봅시다. 일단 클라이언트 계층에서 HTTP 헤더를 기반으로 브라우저 캐싱 가능하고요. 전송 계층에서 CDN 같은 캐싱 솔루션을 활용할 수도 있습니다. 서버 계층에서는 DB 앞에 Redis 같은 인 메모리 캐시 레이어를 구축할 수도 있고, 반복되는 API 요청 또한 캐싱 로직을 다양한 방법으로 구현할 수 있습니다.
어떤 계층에서 캐싱이 동작하든 간에 공통적으로 얻을 수 있는 장점은 빠르고 효율적이라는 것인데요. 캐싱이 동작하는 과정에서 전체적인 요청/응답의 크기나 횟수, 응답을 처리하는 계층의 복잡도가 낮아집니다. 또한 로컬 캐싱을 제외하고는 대부분 컴포넌트 간에 네트워크 구간을 거쳐 통신하기 때문에 전체적인 네트워크 처리량이 경감되는 부가적인 효과도 있습니다. 예시를 함께 살펴보시죠.

위 그림은 CDN 구성 예시입니다. 여러분들도 잘 아시다시피 CloudFront 같은 CDN 서비스는 Client와 Origin 사이에서 정적 및 동적 콘텐츠를 대신 응답(Serving) 해주는 기능을 제공합니다. 효과는 크게 2가지가 있는데요. Client 입장에서는 CDN 계층이 가까운 네트워크 경로에서 캐싱 된 데이터를 우선적으로 제공(응답) 하기 때문에 일단 빠르고요. Origin 입장에서도 상당수의 요청을 CDN 계층에서 대신 처리해 주기 때문에 "응답에 필요한 리소스 수준"을 최소화할 수 있는 장점이 있습니다. 예를 들어 Origin이 Load Balancer – App 서버 – DB 서버 형태로 구성되어 있다면, CDN 구성 전후로 요청량이 off-loading되는 만큼 서버 자원 스펙을 최소화할 수 있고요. 더불어 Edge – LB 간 / LB – App 서버 간 / App 서버 – DB 서버 간에 오가는 네트워크 사용량도 줄어들기 때문에, 그 사이에 유료 구간이 있다면 네트워크 비용도 동시에 절감할 수 있습니다. (물론 Client - Edge처럼 CDN 구성으로 인해 새로 만들어지는 구간의 네트워크 비용도 고려가 필요합니다.)

AWS 환경의 API Gateway 같은 서비스에서도 손쉽게 캐싱을 구현할 수 있습니다. 위처럼 API Gateway 서비스에서 캐싱을 활성화하고 Cache Key와 같은 캐시 조건을 정의하면, 동일한 패턴의 요청에 대해 (백엔드의 실행 계층을 호출하지 않고도) 캐싱 되어 있던 응답 값을 반환할 수 있습니다. 이는 CDN의 동작 방식과 마찬가지로 빠르게 응답하는 효과와 더불어, 백엔드에 전가되는 요청을 최소화함으로써 API 실행 계층의 전체적인 처리 부하를 줄이게 되고요. 만약 API 실행 계층이 Lambda 함수와 연결되어 있고 해당 Lambda 함수에서 다른 AWS 서비스와 다양하게 통신하는(=네트워크 사용량이 누적되는) 로직이 포함되어 있다면, 이 또한 파생되는 네트워크 비용을 최적화하는데 기여할 수 있습니다.

물론 다양한 계층에서 캐싱을 적극적으로 활용하는 것이 네트워크의 사용량을 최적화하는 "직접적인" 수단은 아닙니다. 캐싱의 주목적은 어디까지나 빠른 응답과 응답 계층의 부하 경감이고 모든 상황에서 자유롭게 도입할 수 있는 것도 아닙니다. (예를 들어 응답 값이 실시간성이 아닐 것과 같은 제약조건이 있음) 다만 캐싱은 새로운 응답을 생성하는 계층에서의 처리량을 줄이고, 이 과정에서 "간접적으로" 전체 네트워크 사용량을 줄일 수 있습니다. 그리고 줄어든 네트워크 사용량의 일부가 과금 정책상 유료 구간으로 포함되어 있다면 사용량이 줄어든 만큼의 네트워크 비용을 세이브할 수 있게 됩니다.
셋, 압축을 해보는 건 어떨까?
네트워크의 사용량을 최적화하는 두 번째 전략은 압축(Compress)입니다. 네트워크를 통해 데이터를 주고받을 때 말 그대로 압축 형식의 페이로드를 활용하는 것입니다. 일반적으로 압축 시의 데이터 크기가 압축하지 않았을 때의 데이터 크기보다 작을 테니 네트워크의 사용량을 산정할 때도 전자가 당연히 유리하고요. 레거시 환경과 달리 클라우드 환경은 내부 통신에도 과금하는 경우가 종종 있기 때문에, 이렇게 경량화된 형태로 데이터를 주고받는 것이 의도치 않게 비용 측면에서 이점을 가질 수 있습니다.
그럼 데이터를 압축하고 전송하고 해제하는 로직은 어디서 구현해야 할까요? 이 부분은 사실 애플리케이션에서 각자 구현해야 하는 영역입니다. 따라서 이런 개별성이 강한 영역을 여기서 일괄적으로 다루기는 힘들고요. 대신 클라우드의 관리형 서비스에서 압축 기능을 옵션처럼 활성화하는 방법도 있습니다. 이 영역은 해당 서비스를 사용 중이라면 공통적으로 검토할 수 있는 부분이기도 하고요. 상대적으로 적용이 쉽고 효과도 즉각적이어서 AWS 서비스 기준으로 몇 가지 예시를 소개해 드리겠습니다.
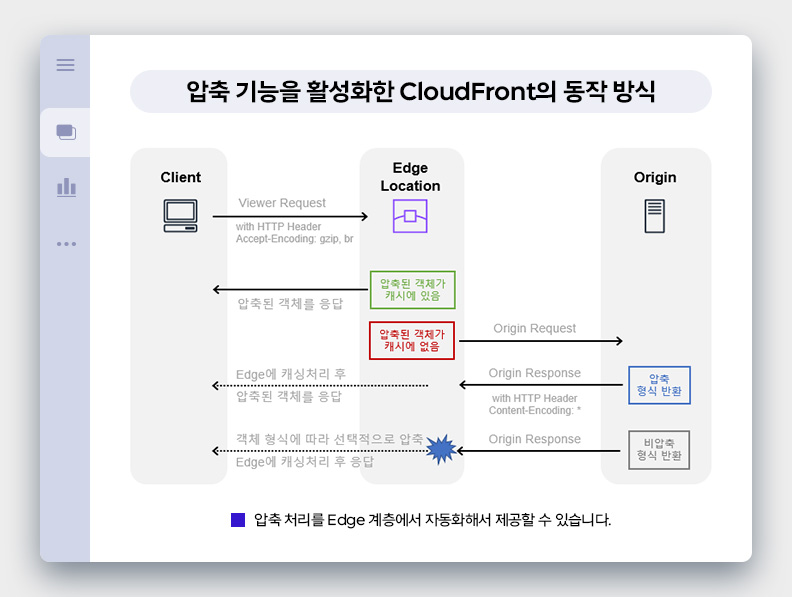
첫 번째는 CloudFront에서 압축된 전송 기능을 활성화한 예시입니다. 위처럼 동작 방식을 간단히 그려봤는데요. 처음 Viewer Request에서 "압축 형식으로 인코딩된 객체를 수용할 수 있음"을 HTTP 헤더 정보를 통해 알립니다. CloudFront는 압축 형식의 객체가 캐싱 되어 있는지 확인하게 되고요. 있다면 해당 객체를 클라이언트에게 제공합니다. 만약 없다면 Origin에게 원본 객체를 요청하게 되고, Origin이 압축 형식으로 반환하는 경우 이를 캐싱 처리한 후 클라이언트에게도 전달합니다. 만일 Origin이 비압축 형식으로 반환한 경우, CloudFront는 압축 가능 여부를 판단하고 선택적으로 압축 및 캐싱 처리 후 클라이언트에게 전달합니다. 위와 비슷한 로직을 Lambda@Edge 같은 계층에서 별도로 구현할 수도 있습니다.

복잡한 동작 방식을 여러분들이 모두 이해할 필요는 없고요. 이런 파이프라인이 동작할 때의 효과에만 주목하시면 됩니다. 위 그림을 보시면 AWS의 과금 정책상 비용이 발생하는 구간은 Viewer Response인데요. 나머지 3개의 구간(Viewer Request, Origin Request/Response)은 (Origin의 위치에 따라 다르지만) 대개 과금하지 않는 구간입니다. 결국 CDN 계층에서 클라이언트에게 압축 형식으로 응답하도록 만들어 놓으면, Viewer Request 구간의 네트워크 사용량이 크게 감소하게 됩니다. 만약 해당 구간의 전송 단가가 GB 당 100원이고 비압축 시 10TB인 객체들을 압축하여 1TB로 서빙했다면, 네트워크 비용이 100만 원에서 10만 원으로 줄어드는 셈입니다.

API Gateway 같은 서비스에서도 압축 옵션을 활성화할 수 있습니다. 위 그림처럼 서비스 옵션에서 Content Encoding 기능을 활성화하면, API Gateway가 응답할 때 (클라이언트가 허용하는 인코딩 방식을 기준으로) Body 값을 압축하여 반환합니다. 결과적으로 API Gateway가 응답하는 크기를 최소화하여 네트워크 사용량을 최적화할 수 있습니다. 이때 API를 요청하는 클라이언트가 인터넷 구간에 있다면 Data Transfer Out 비용을 줄일 수 있고, 다른 Account의 자원에서 Transit Gateway를 거쳐 요청했다면 Transit Gateway 구간의 처리 비용을 줄일 수 있습니다.
요즘은 좀 찾아보기 힘들지만 예전에는 WAN 최적화를 통해 특정 구간의 네트워크 성능을 최적화해주는 솔루션들이 있었는데요. 그런 솔루션의 내부 엔진을 들여다보면 압축 / 캐싱 / 중복제거 등의 기술을 복합적으로 활용하고 있습니다. 결국 제한된 네트워크 환경에서 주고받는 데이터의 양을 최소화하는 공통 기법이 압축 / 캐싱 / 중복제거라는 뜻이기도 하고요. 이는 클라우드 환경에서도 네트워크 사용량을 최적화하는데 동일하게 적용 가능한 기법이고 과금 정책과 결합하면 비용 최적화 방안으로도 확장시킬 수 있습니다.
넷, 다른 새로운 접근은 없을까?
캐싱과 압축 외에 네트워크의 사용량을 최적화하는 다른 방법은 없을까요? 이번에는 관점을 좀 바꿔서 "AWS의 각 네트워크 구간별"로 사용량을 줄일 수 있는 아이디어를 3가지 카테고리로 나눠서 살펴보겠습니다.
첫 번째는 AWS 환경에서 인터넷으로 나가는 구간입니다. Data Transfer Out 항목인데요. 한 가지 상황을 가정해 보겠습니다. 여러분들이 On-Premise 환경에 대규모 로그분석 시스템을 구축 중이고, AWS의 S3에 적재된 로그 중 작년 1년간의 데이터(약 320TB)를 이관해야 하는 상황입니다. 즉 AWS 내 환경에서 AWS 외 환경으로 데이터를 끄집어 내야 하는 상황인데요. 일반적으로 AWS 환경으로 인입되는 트래픽은 무료지만 반대 방향은 상대적으로 전송 단가가 높습니다. 그래서 인터넷 구간을 거쳐 데이터를 마이그레이션했을 때 비용을 추산해 보니 약 5,000만 원이 산출되네요. Direct Connect 연결도 검토해 봤지만 전송 단가는 낮아지나 일회성 연결 유지 비용까지 고려하면 큰 이득이 없었습니다. 더구나 On Premise 쪽 네트워크 대역폭도 제한이 있어서 전송 소요 시간에도 이슈가 있는 상황입니다.

이때 AWS Snowball이라는 서비스를 통해 데이터를 마이그레이션하는 방안을 고민해 볼 수 있습니다. 기존 마이그레이션 방안에서 고민했던 "Data Transfer Out 구간의 네트워크 사용량"을 오프라인 방식으로 대체하는 것입니다. 비용을 추산하면 디바이스 대여 비용 200만 원, S3에서 Snowball 장비로 데이터를 Export 하는 비용 2,200만 원이 산출되었습니다. 두 비용을 합치면 2,400만 원 정도의 비용이 발생하는 셈입니다. 이관 비용은 기존 온라인 마이그레이션에 비해 50% 이상 감소하였고, 오프라인으로 데이터를 옮기기 때문에 On Premise 환경의 네트워크 대역폭을 점유하는 문제(+전송 소요시간 이슈)도 해결되었습니다.

Data Transfer Out 사용량을 어떻게든 줄인다는 관점에서는 비정상적인 요청을 차단하는 것도 또 하나의 방법이 됩니다. 예를 들어 CloudFront이 구성된 환경에서 해당 Edge 계층에 AWS Shield나 AWS WAF 같은 보안 서비스를 add-on 하였습니다. 그 결과 보안적으로 위험한 패턴의 요청들을 필터링하게 되었고, 그 필터링 과정에서 각종 봇이나 크롤러의 반복된 요청도 차단할 수 있게 되었습니다. DDoS 형태의 외부 공격도 일부 패턴을 차단하여 서비스 영향도를 최소화하였습니다. 이때 보안 서비스 도입의 직접적인 효과는 보안성 개선 및 서비스 안정성 향상입니다. 더불어 비정상으로 분류된 요청을 사전에 차단하고 응답하지 않음으로써, 전체적인 Data Transfer Out 사용량이 줄어드는 간접적인 효과도 거둘 수 있었습니다.
두 번째는 AWS 환경 내에서 AZ에 걸쳐(Cross-AZ) 오가는 트래픽 구간입니다. 글 서두에 말씀드렸던 것처럼 동일 AZ 간 통신은 무료인데 반해 서로 다른 AZ 간 통신은 양쪽 모두에서 비용이 발생합니다. 따라서 설계상으로 서로 다른 AZ 간 트래픽을 최소화하면 네트워크 비용을 최적화할 수 있습니다. 예를 한번 들어볼까요?

직관적인 이해를 위해 아주 극단적인 예시를 하나 가져왔습니다. 여러분도 아시다시피 AWS EFS 서비스는 공유 스토리지 서비스인데요. EFS 서비스에서는 해당 저장소와 연결된 Mount Point를 AZ(Subnet)별로 생성할 수 있습니다. 그리고 위와 같이 각 EC2에서 EFS 파일시스템을 마운트 할 때 동일한 AZ의 MountPoint를 사용하면 되는데요. 위 그림은 올바른 예라서 구성상에 전혀 문제가 없습니다.

이번엔 구성의 나쁜 예시입니다. 자주 발생하는 사례는 아니고요. 각 EC2가 다른 AZ에 위치한 MountPoint에 연결되어 있습니다. 동일 VPC 내 통신이기 때문에 Security Group 같은 방화벽만 통과한다면 정상적으로 마운트가 됩니다. 문제는 EC2와 EFS 간에 오가는 모든 입출력 작업이 Cross-AZ의 네트워크 사용량으로 집계됩니다. 이 경우는 마운트 시 파일시스템의 주소값을 도메인 주소가 아닌 특정 IP로 임의할당 했을때 종종 발생하는데요. 사용자가 주소값을 도메인으로 지정하는 경우 DNS 레벨에서 "동일 AZ에 생성된 MountPoint의 IP주소"를 반환하도록 설계되어 있어 이런 이슈가 발생하는 것을 방지할 수 있습니다.
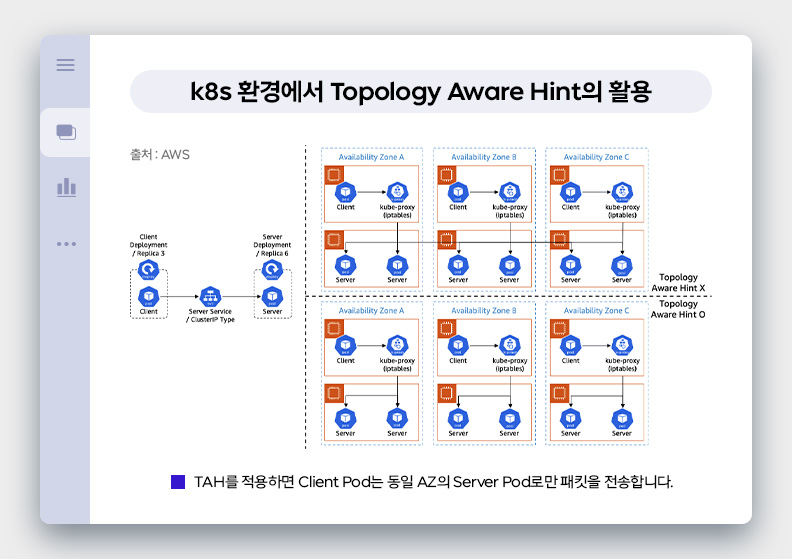
위와 같이 컨테이너 환경에서 Cross-AZ 통신을 최소화하는 방법도 있습니다. Topology Aware Hint라는 것인데요. 위 그림은 Cluster IP 이용 시 TAH 미적용 시와 TAH 적용 시에 Client Pod와 Server Pod 간 통신 범위가 어떻게 달라지는지를 보여주고 있습니다. TAH를 적용하게 되면 Client pod는 kube-proxy가 제어하는 iptables 규칙에 따라 동일한 AZ의 Server pod에게만 패킷을 전송합니다. 따라서 Client pod와 Server pod 간에 Cross-AZ 간 통신이 발생하지 않으며 이는 해당 구간의 네트워크 비용을 최적화하는 데 도움이 됩니다. (물론 이런 형태의 구성을 가져가면 가용성을 일부 훼손하는 등의 단점도 있어서 적용 여부 결정시 다양한 변수를 함께 고려해야 합니다.)
세 번째는 구성상 네트워크 홉을 최대한 줄이라는 것입니다. 예를 들어 AWS 환경과 On-Premise 환경이 Direct Connect로 연결되어 있습니다. 이때 AWS 환경이 다수의 AWS 계정과 VPC 등으로 분산되어 있는 경우 Transit Gateway 같은 연동 계층을 만들어 Direct Connect Gateway에 연결할 수 있는데요. 이때 발생 가능한 비용 이슈는 AWS 환경과 On-Premise 구간 통신 시 "Transit Gateway 처리 비용"과 "Direct Connect 전송 비용"이 동시에(따로따로) 발생한다는 것입니다. 특히 전체적인 네트워크 트래픽의 규모가 클 때, 이런 네트워크 홉이 늘어나면 늘어날수록 더 많은 네트워크 비용이 발생합니다. 레거시 환경과 달리 클라우드 환경에서 이런 부작용이 두드러지는 이유는 대부분의 과금 구조가 피크치가 아닌 누적 사용량 기반이기 때문입니다.

위에서 말씀드린 사례 외에도 다양한 방법으로 다양한 구간에서 네트워크 사용량을 최적화할 수 있습니다. Disaster Recovery(재해 복구) 환경을 구성하고 2개의 Region을 Active - Standby로 설정했다고 가정해 보겠습니다. 이때 Active 리전에서 Standby 리전 방향으로 데이터가 주기적으로 복제되는데요. 이 복제 데이터를 가급적 Full Data가 아닌 변경 분 위주(증분 방식)로 셋업 하면 Region 간 네트워크 비용(=사용량)을 최적화할 수 있습니다. 한가지 예를 더 들어볼까요? 여러분은 쿠팡 플레이 같은 비디오 스트리밍 서비스를 제공하고 있습니다. 이때 클라이언트의 환경(디바이스 특성 또는 네트워크 대역폭 등)에 따라 각기 다른 비트 레이트의 원본을 제공하면, 서비스 수준을 표준화함과 동시에 네트워크 전송량도 최적화할 수 있습니다.
마치며
이제 이야기를 마무리할 시간입니다. 오늘 다루는 내용들은 단위 주제들을 묶어서 다루다 보니 큰 흐름에서 벗어나는 지엽적인 예시들은 가급적 생략했고요. "네트워크 구간별로 사용량을 계측하는 법"도 정리하다 보니 분량이 너무 늘어나서 마지막 다듬는 과정에서 제외했습니다. 5회차 단가 편에서 다뤘던 주제들도 가급적 중복되지 않도록 내용을 재구성했습니다.
오늘 제가 주로 전달하고 싶었던 이야기는 "클라우드 서비스 계층의 조작만으로" (애플리케이션의 수정 없이) 최적화할 수 있는 포인트들이었는데요. 네트워크의 사용량 최적화는 컴퓨팅이나 스토리지에 비해 그런 영역이 많지 않아서, 제한된 카테고리로 내용을 전개하기가 힘들었습니다. 사실 제 역할은 모든 정답을 제공하는 것이 아니고, 여러분들에게 최적화 방향성을 설득하고 (각자의 경험이 뒤섞인) 새로운 영감을 불러일으키는 것이니까요. 그런 의도만 잘 전달되었으면 좋겠습니다.
프롤로그 2편, 본론 6편까지 총 8회차가 완료되었고요. 이제 에필로그 2편이 남았습니다. 남은 2회차는 특정한 메인 주제 없이 자유로운 방식으로 다양한 꿀팁들을 적어볼 생각입니다. 지금 구상 중인 주제는 "미사용 자원을 판단하는 법", "요금 페이지 제대로 읽는 법", "빌링 데이터를 빠르게 검토하는 기준", "Organization 같은 통합 환경의 고려 사항", "2개 이상의 서비스가 서로 영향을 주고받는 과금 포인트" 같은 것들인데요. 작성하다 보면 없어질 수도 있고 또 다른 주제가 튀어나올 수도 있으니 마지막까지 많은 관심을 부탁드리고요. 그럼 9회차에서 뵙도록 하겠습니다. 끝!
▶ 더 읽어보기
- 클라우드 비용 최적화 로드맵 #1 - 연재를 시작하며
- 클라우드 비용 최적화 로드맵 #2 - 비용을 자세히 보기 위한 준비
- 클라우드 비용 최적화 로드맵 #3 - 컴퓨팅의 단가를 최적화하는 법
- 클라우드 비용 최적화 로드맵 #4 - 스토리지의 단가를 최적화하는 법
- 클라우드 비용 최적화 로드맵 #5 - 네트워크의 단가를 최적화하는 법
- 클라우드 비용 최적화 로드맵 #6 - 컴퓨팅의 사용량을 최적화하는 법
- 클라우드 비용 최적화 로드맵 #7 - 스토리지의 사용량을 최적화하는 법
▶ 최준승 님 / Cloud Architect 팀 / jsch@sk.com
'What's New' 카테고리의 다른 글
| 클라우드 비용 최적화 로드맵 #9 - FinOps 성숙 모델 5단계 따라가기 (2) | 2024.12.24 |
|---|---|
| 클라우드 비용 최적화 로드맵 #7 - 스토리지의 사용량을 최적화하는 법 (1) | 2024.12.11 |
| 클라우드 비용 최적화 로드맵 #6 - 컴퓨팅의 사용량을 최적화하는 법 (0) | 2024.10.17 |
| 클라우드 비용 최적화 로드맵 #5 - 네트워크의 단가를 최적화하는 법 (4) | 2024.10.10 |
| 클라우드 비용 최적화 로드맵 #4 - 스토리지의 단가를 최적화하는 법 (2) | 2024.10.04 |